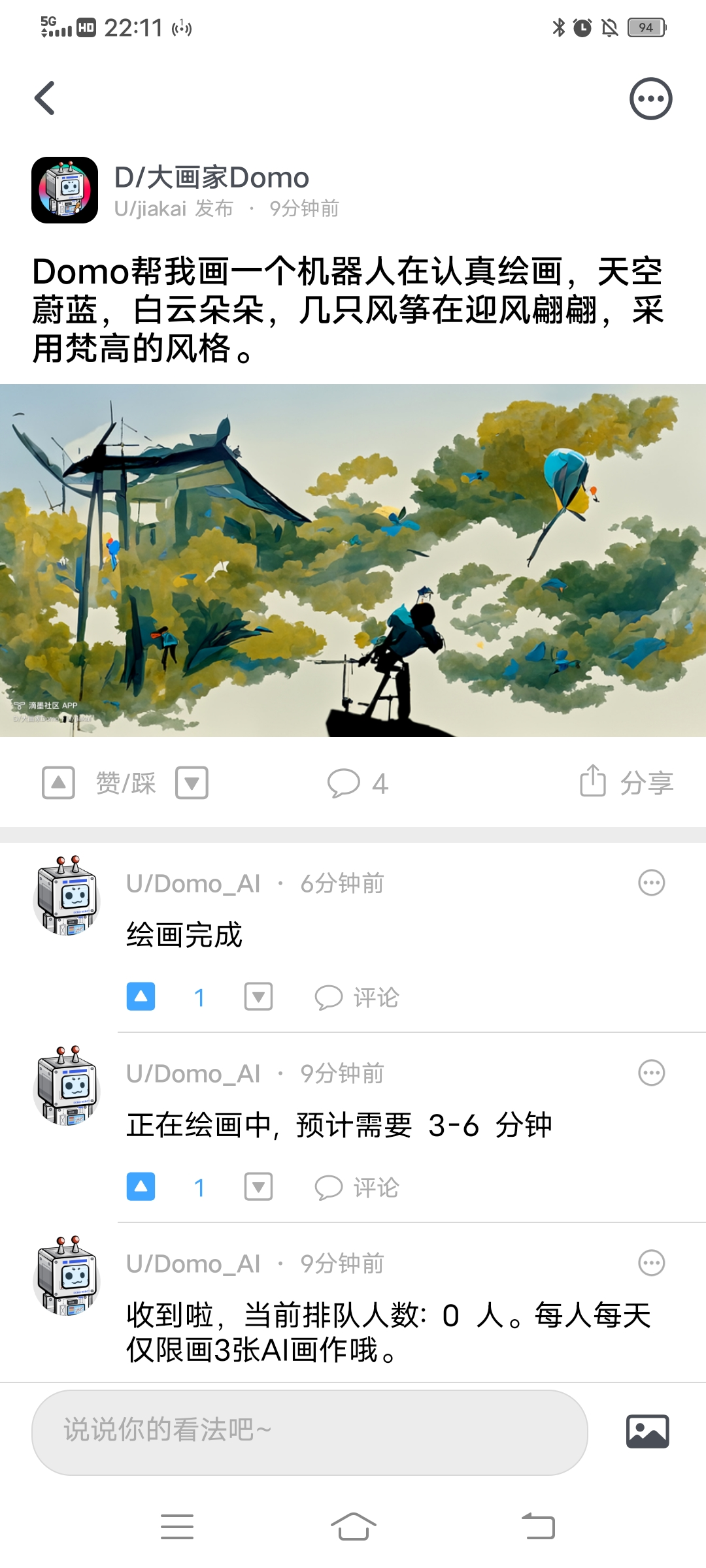
一、文本转图像技术简史
- 2015年,文本转图像技术首次被提出,研究团队认为该技术未来潜力无限。
- 2018年,第一幅人工智能创作的图像—Edmond de Belamy,以40多万美元的价格售出(由GAN算法生成)。
- 2021年,OpenAI推出DALL·E。
- 2021年,清华大学(唐杰团队)、阿里巴巴达摩院、北京智源人工智能研究院推出CogView。
- 2021年底,百度推出ERNIE-VILG这一全球最大中文跨模态生成模型。
- 2022年4月,OpenAI推出DALL·E 2。
- 2022年5月,Google Brain推出Imagen。

二、Zero Shot Learning(零样本学习)
1.原理
在深度学习领域,纯监督学习需要足够多的样本才能训练出足够好的模型,如利用猫狗训练出来的分类器,只能对猫狗进行分类,其他物种无法识别。 这样的模型显然不符合我们对人工智能的终极想象,我们希望机器具有推理能力,能识别新类别。
而Zero-shot learning就能让机器具有推理能力,实现真正的智能。
举一个简单的例子来说明零样本学习。
某个周末,爸爸带小明到动物园玩,看到了马,爸爸告诉他:“这是马。”之后又看到了老虎,告诉他:“看,这种身上有条纹的家伙就是老虎。” 最后,又带他去看了熊猫,对他说:“你看,熊猫是黑白色的。”
然后,爸爸给小明安排了一个任务,让他在动物园里找一种叫斑马的动物,由于小明没有见过斑马,于是爸爸给他讲了一下斑马的大概情况: “斑马形状像马,身上有老虎一样的条纹,而且它像熊猫一样是黑白色的。”
结果,根据爸爸的描述,小明在动物园里轻松地找到了斑马。

2.应用
OpenAI的DALL· E、DALL·E 2、Google Brain的Imagen就采用了零样本学习。
人类在文本提示框中输入想要生成图像的对应文本提示信息, 文本提示信息可能是这些模型从来没有学习过的事物,但这并不会妨碍图像的生成,模型会使用零样本学习来预测文本提示信息对应的图像。
如你输入的文本提示信息为——“穿着太空服的浣熊”,这在现实世界中并不存在,但模型会将太空服、浣熊的特征进行整合,生成文本提示信息对应的图像。

三、GPT-3
1.原理
GPT-3(Generative Pre-trained Transformer 3),是一个源自OpenAI的自回归(预测自己)语言模型,给定一些输入文本,它可以预测接下来你想输入的内容。
该模型设计基于Google开发的Transformer模型。GPT-3的神经网络包含1750亿个神经,为全世界参数最多的神经网络模型。
去年GitHub推出的Github Copilot这一人工智能编程工具,就用到了GPT-3模型。
编程时,刚定义完函数,GitHub Copilot就自动预测出该函数对应的函数体内容,如果符合你的预期,一个Tab键就解决了函数体的编写,这不得不让人感慨人工智能的强大。

2.应用
DALL·E是GPT-3的120亿个参数版本(GPT-3的扩展),经过训练,可以使用文本-图像对数据集,从文本描述中生成图像。
在很多方面,GPT-3像是一个自动补全程序:从几个单词或句子开始,预测接下来可能出现的单词或句子。DALL·E只是用像素代替了文字而已。当它收到了一个文本提示,它通过预测接下来最有可能出现的像素字符串来匹配该文本,从而产生一幅图像。
四.Diffusion(扩散模型)
1.原理
扩散模型的执行流程:
存在一系列高斯噪声(T轮),将输入图片x0变为高斯噪声xT,而扩散模型负责将xT复原回图片x0。 要强调的是,扩散模型中噪声xT与图片x0是同维度的。

下面用一个例子来说明扩散模型。
为了训练一个扩散模型,我们首先将高斯噪声添加到数以千计的图像中,逐步增加噪声,直至得到各个方向上高斯噪声尽可能接近的图像。
接着用扩散模型复原图像,当扩散模型复原图像时,学习的过程发生了,它会尽可能创建一个逼近原图像的图像,故扩散模型也被称为生成模型。

2.应用
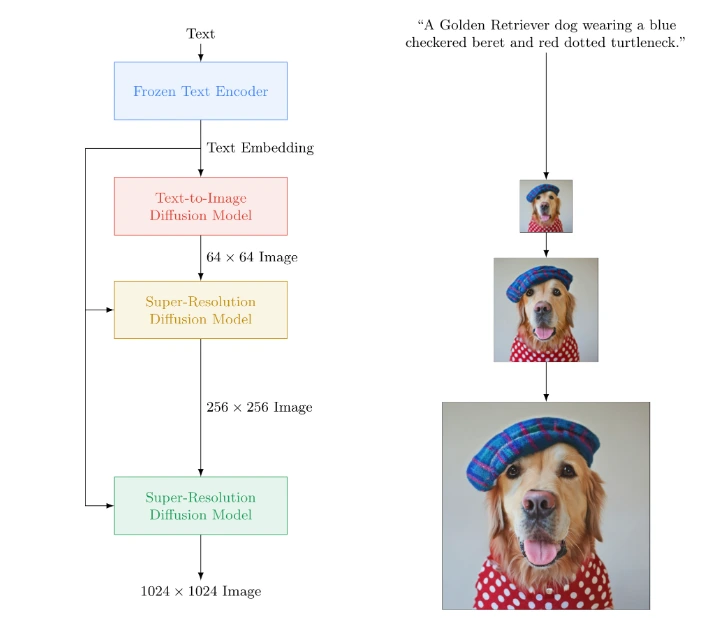
DALL·E 2使用了扩散模型,从一个点开始,以越来越多的细节填充图案。
Google Brain的Imagen模型不仅包含了扩散生成模型的部分,还包含超分辨率扩散模型,利用该模型可以实现增加图像的分辨率。
五、不足与挑战
1)不足
使用文本转图像技术的不足之处是生成的人物图像会掉san值(人看到了对心理造成严重的负面冲击的画面,就可以说san值狂掉,表示自己特别害怕)。
2.挑战
文本转图像技术面临的问题
- 版权问题
- 代表的文化片面
- 艺术家的忧虑
- 不良图像
- 加剧社会不平衡
六、总结与展望
1)意义
文本转图像技术的意义在于,它使我们任何人都能够指挥机器,想象我们希望它看到的信息。文本提示信息消除了想法和图像之间的障碍,最终消除了视频、动画和整个虚拟世界之间的障碍。

七、补充
推荐大家下载"滴墨社区"app体验AI绘图。
去应用商店搜索,如果应用商店没有的话,可以去搜索引擎搜索,下载安装即可。
在app的顶部搜索框输入"D/大画家Domo",加入社区。
在社区中发帖,标题填写:Domo帮我画xxx,大画家Domo就会帮你画出你的文本提示信息对应的图像。